PythonでWebサイトのソースコードを取得して差分を抽出するツール作った
Posted at: 2019-04-23
テスト環境と本番環境、もしくは新旧サーバ内のWebページの差分を抽出して比較する必要があったのですが、対象のページがかなり多かったためPythonでスクリプトを書いて自動化しました。
今後もちょこちょこ使うことがありそうだったり、エンジニア以外のメンバーも使用できるようにしておこうということでDockerを使用してツール化したので公開しておきます。
どなたかの参考になれば。
こんな感じでソースの差異を吐き出してくれます。
結果一覧:
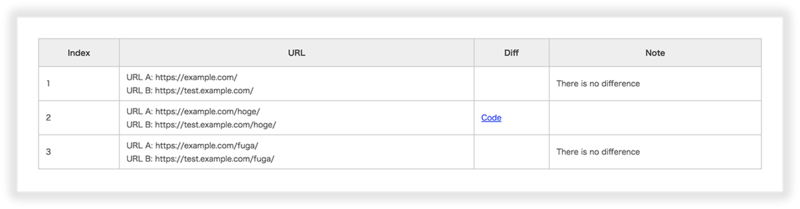
差分詳細:

ソースコードはこちら
GitHub - zenpachi/extract-html-differences
端末ごとの環境の差異による不具合や、エンジニア以外のメンバーの端末で環境を整えるのが面倒だったので今回はDockerを使用しましたが、Dockerを使わずにPythonで実行することもできます。
DockerImageはDockerHubにて公開しているので、Docker Desktop for Macなどがインストールされていれば上記リポジトリのdiff.shだけですぐに使用できます。
カスタマイズが必要であれば上記リポジトリのDockerfileやPythonコードを改変してください。
使い方
README.mdに書いてある通りですが一応こちらにも。
Dockerでツールを使用する
Dockerを使用できる環境であることが前提です。
Docker Desktop for Mac
1. 上記リポジトリのdiff.shをダウンロードする
extract-html-differences/diff.sh at master · zenpachi/extract-html-differences · GitHub
2. CSVファイルを作る
差分抽出をしたいURLをリスト化したCSVファイルを作ります。
サンプル:
1,https://example.com/,https://test.example.com/
2,https://example.com/page1,https://test.example.com/page1
3,https://example.com/page2,https://test.example.com/page2
3. プログラムを実行する
$ cd <downloadPath>
$ ./diff.sh
4. 指示通りに設定を入力していく
$ ./diff.sh
Path of CSV file: <csvFilePath> # 作成したURLリストのCSVのパス
Path for the output: <outputResultPath> # 差分抽出した結果を吐き出すパス
Number of multithreading: (1) 1 # マルチスレッドの数。大きいほど早く処理が進みますが、サーバへの負荷は高くなるので注意してください。
Waiting time to request page (ms): (1000) 1000 # リクエストごとに待機する時間。サーバへの負荷を調整します。
CSV file : 'entered csvFilePath'
output : 'entered outputResultPath'
Threads : 1
Wait time(ms) : 1000
Are you sure you want to continue? [y/N] y
これであとは待っていれば結果がoutputPathに吐き出されます。
Dockerを使用せずにツールを使用する
Python3系といくつかのライブラリが必要になります。
1. 上記リポジトリをcloneする
$ git clone https://github.com/zenpachi/extract-html-differences.git
2. CSVファイルを作る
差分抽出をしたいURLをリスト化したCSVファイルを作ります。
サンプル:
1,https://example.com/,https://test.example.com/
2,https://example.com/page1,https://test.example.com/page1
3,https://example.com/page2,https://test.example.com/page2
3. ライブラリをインストールする
$ pip3 install beautifulsoup4 pandas html5lib
4. プログラムを実行する
$ ./diff_without_docker.sh
4. 指示通りに設定を入力していく
$ ./diff_without_docker.sh
Path of CSV file: <csvFilePath> # 作成したURLリストのCSVのパス
Path for the output: <outputResultPath> # 差分抽出した結果を吐き出すパス
Number of multithreading: (1) 1 # マルチスレッドの数。大きいほど早く処理が進みますが、サーバへの負荷は高くなるので注意してください。
Waiting time to request page (ms): (1000) 1000 # リクエストごとに待機する時間。サーバへの負荷を調整します。
CSV file : 'entered csvFilePath'
output : 'entered outputResultPath'
Threads : 1
Wait time(ms) : 1000
Are you sure you want to continue? [y/N] y
これであとは待っていれば結果がoutputPathに吐き出されます。
差分抽出結果
結果は全体の結果をまとめた_index.html、_result.csvというファイルとURLごとの差分結果であるhtmlファイルで生成されます。
_index.htmlをブラウザで開くか、_result.csvをGoogleSpreadSheetやMicrosoft Excelもしくはテキストエディタなどで開いてください。
注意点
- 短い間隔で同一Webサイトに連続してアクセスするとサーバに負荷がかかります。悪用しないでください。またサーバへのアクセスを拒否されたりする可能性があります。
- 本ツールは自身が保有・管理するWebサイト・アプリケーションに対しての使用を目的とするツールです。第三者の保有するWebサイト・アプリケーションへの使用は法律・規約に抵触する可能性がありますのでご注意ください。
- ツールの使用は自己責任でお願いします。ツールの使用によって生じたいかなる損害に対しても作者は一切の責任を負いかねます。
ソースコードなど
GitHub - zenpachi/extract-html-differences
Docker Hub - zenpachi/extract-html-differences